Go 高性能编程
https://geektutu.com/post/high-performance-go.html
常用数据结构
字符串高效拼接
在 Go 语言中,字符串 (string) 是不可变的,拼接字符串事实上是创建了一个新的字符串对象。
如果代码中存在大量的字符串拼接,对性能会产生严重的影响。
常见的拼接方式
为了避免编译器优化,我们首先实现一个生成长度为 n 的随机字符串的函数。
const letterBytes = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
func randomString(n int) string {
b := make([]byte, n)
for i := range b {
b[i] = letterBytes[rand.Intn(len(letterBytes))]
}
return string(b)
}
然后利用这个函数生成字符串 str,然后将 str 拼接 N 次。在 Go 语言中,常见的字符串拼接方式有如下 5 种:
- 使用
+
func plusConcat(n int, str string) string {
s := ""
for i := 0; i < n; i++ {
s += str
}
return s
}
- 使用
fmt.Sprintf
func sprintfConcat(n int, str string) string {
s := ""
for i := 0; i < n; i++ {
s = fmt.Sprintf("%s%s", s, str)
}
return s
}
- 使用
strings.Builder
func builderConcat(n int, str string) string {
var builder strings.Builder
for i := 0; i < n; i++ {
builder.WriteString(str)
}
return builder.String()
}
- 使用
bytes.Buffer
func bufferConcat(n int, s string) string {
buf := new(bytes.Buffer)
for i := 0; i < n; i++ {
buf.WriteString(s)
}
return buf.String()
}
- 使用
[]byte
func byteConcat(n int, str string) string {
buf := make([]byte, 0)
for i := 0; i < n; i++ {
buf = append(buf, str...)
}
return string(buf)
}
如果长度是可预知的,那么创建 []byte 时,我们还可以预分配切片的容量(cap)。
func preByteConcat(n int, str string) string {
buf := make([]byte, 0, n*len(str))
for i := 0; i < n; i++ {
buf = append(buf, str...)
}
return string(buf)
}
make([]byte, 0, n*len(str))第二个参数是长度,第三个参数是容量 (cap),切片创建时,将预分配 cap 大小的内存。
benchmark 性能比拼
每个 benchmark 用例中,生成了一个长度为 10 的字符串,并拼接 1w 次。
func benchmark(b *testing.B, f func(int, string) string) {
var str = randomString(10)
for i := 0; i < b.N; i++ {
f(10000, str)
}
}
func BenchmarkPlusConcat(b *testing.B) { benchmark(b, plusConcat) }
func BenchmarkSprintfConcat(b *testing.B) { benchmark(b, sprintfConcat) }
func BenchmarkBuilderConcat(b *testing.B) { benchmark(b, builderConcat) }
func BenchmarkBufferConcat(b *testing.B) { benchmark(b, bufferConcat) }
func BenchmarkByteConcat(b *testing.B) { benchmark(b, byteConcat) }
func BenchmarkPreByteConcat(b *testing.B) { benchmark(b, preByteConcat) }
运行该用例:
$ go test -bench="Concat$" -benchmem .
goos: darwin
goarch: amd64
pkg: example
BenchmarkPlusConcat-8 19 56 ms/op 530 MB/op 10026 allocs/op
BenchmarkSprintfConcat-8 10 112 ms/op 835 MB/op 37435 allocs/op
BenchmarkBuilderConcat-8 8901 0.13 ms/op 0.5 MB/op 23 allocs/op
BenchmarkBufferConcat-8 8130 0.14 ms/op 0.4 MB/op 13 allocs/op
BenchmarkByteConcat-8 8984 0.12 ms/op 0.6 MB/op 24 allocs/op
BenchmarkPreByteConcat-8 17379 0.07 ms/op 0.2 MB/op 2 allocs/op
PASS
ok example 8.627s
从基准测试的结果来看,使用 + 和 fmt.Sprintf 的效率是最低的,和其余的方式相比,性能相差约 1000 倍,而且消耗了超过 1000 倍的内存。当然 fmt.Sprintf 通常是用来格式化字符串的,一般不会用来拼接字符串。
strings.Builder、bytes.Buffer 和 []byte 的性能差距不大,而且消耗的内存也十分接近,性能最好且消耗内存最小的是 preByteConcat,这种方式预分配了内存,在字符串拼接的过程中,不需要进行字符串的拷贝,也不需要分配新的内存,因此性能最好,且内存消耗最小。
建议
综合易用性和性能,一般推荐使用 strings.Builder 来拼接字符串。
这是 Go 官方对 strings.Builder 的解释:
A Builder is used to efficiently build a string using Write methods. It minimizes memory copying.
string.Builder 也提供了预分配内存的方式 Grow:
func builderConcat(n int, str string) string {
var builder strings.Builder
builder.Grow(n * len(str))
for i := 0; i < n; i++ {
builder.WriteString(str)
}
return builder.String()
}
使用了 Grow 优化后的版本的 benchmark 结果如下:
BenchmarkBuilderConcat-8 16855 0.07 ns/op 0.1 MB/op 1 allocs/op
BenchmarkPreByteConcat-8 17379 0.07 ms/op 0.2 MB/op 2 allocs/op
与预分配内存的 []byte 相比,因为省去了 []byte 和字符串 (string) 之间的转换,内存分配次数还减少了 1 次,内存消耗减半。
性能背后的原理
比较 strings.Builder 和 +
strings.Builder 和 + 性能和内存消耗差距如此巨大,是因为两者的内存分配方式不一样。
字符串在 Go 语言中是不可变类型,占用内存大小是固定的,当使用 + 拼接 2 个字符串时,生成一个新的字符串,那么就需要开辟一段新的空间,新空间的大小是原来两个字符串的大小之和。拼接第三个字符串时,再开辟一段新空间,新空间大小是三个字符串大小之和,以此类推。
假设一个字符串大小为 10 byte,拼接 1w 次,需要申请的内存大小为:
10 + 2 * 10 + 3 * 10 + ... + 10000 * 10 byte = 500 MB
而 strings.Builder,bytes.Buffer,包括切片 []byte 的内存是以倍数申请的。例如,初始大小为 0,当第一次写入大小为 10 byte 的字符串时,则会申请大小为 16 byte 的内存(恰好大于 10 byte 的 2 的指数),第二次写入 10 byte 时,内存不够,则申请 32 byte 的内存,第三次写入内存足够,则不申请新的,以此类推。在实际过程中,超过一定大小,比如 2048 byte 后,申请策略上会有些许调整。我们可以通过打印 builder.Cap() 查看字符串拼接过程中,strings.Builder 的内存申请过程。
func TestBuilderConcat(t *testing.T) {
var str = randomString(10)
var builder strings.Builder
cap := 0
for i := 0; i < 10000; i++ {
if builder.Cap() != cap {
fmt.Print(builder.Cap(), " ")
cap = builder.Cap()
}
builder.WriteString(str)
}
}
运行结果如下:
$ go test -run="TestBuilderConcat" . -v
=== RUN TestBuilderConcat
16 32 64 128 256 512 1024 2048 2688 3456 4864 6144 8192 10240 13568 18432 24576 32768 40960 57344 73728 98304 122880 --- PASS: TestBuilderConcat (0.00s)
PASS
ok example 0.007s
我们可以看到,2048 以前按倍数申请,2048 之后,以 640 递增,最后一次递增 24576 到 122880。总共申请的内存大小约 0.52 MB,约为上一种方式的千分之一。
16 + 32 + 64 + ... + 122880 = 0.52 MB
比较 strings.Builder 和 bytes.Buffer
strings.Builder 和 bytes.Buffer 底层都是 []byte 数组,但 strings.Builder 性能比 bytes.Buffer 略快约 10% 。
一个比较重要的区别在于
bytes.Buffer转化为字符串时重新申请了一块空间,存放生成的字符串变量strings.Builder直接将底层的[]byte转换成了字符串类型返回了回来。
bytes.Buffer:
// To build strings more efficiently, see the strings.Builder type.
func (b *Buffer) String() string {
if b == nil {
// Special case, useful in debugging.
return "<nil>"
}
return string(b.buf[b.off:])
}
strings.Builder:
// String returns the accumulated string.
func (b *Builder) String() string {
return *(*string)(unsafe.Pointer(&b.buf))
}
bytes.Buffer 的注释中还特意提到了:
To build strings more efficiently, see the strings.Builder type.
切片 (slice) 性能及陷阱
切片的本质
在 Go 语言中,切片 (slice) 可能是使用最为频繁的数据结构之一,切片类型为处理同类型数据序列提供一个方便而高效的方式。
数组
Go 的切片 (slice) 是在数组 (array) 之上的抽象数据类型,数组类型定义了长度和元素类型。例如, [3]int 类型表示由 3 个 int 整型组成的数组,数组以索引方式访问,例如表达式 s[n] 访问数组的第 n 个元素。数组的长度是��固定的,长度是数组类型的一部分。长度不同的 2 个数组是不可以相互赋值的,因为这 2 个数组属于不同的类型。例如下面的代码是不合法的:
a := [3]int{1, 2, 3}
b := [4]int{2, 4, 5, 6}
a = b // cannot use b (type [4]int) as type [3]int in assignment
在 C 语言中,数组变量是指向第一个元素的指针,但是 Go 语言中并不是。
Go 语言中,数组变量属于值类型(value type),因此当一个数组变量被赋值或者传递时,实际上会复制整个数组。例如,将 a 赋值给 b,修改 a 中的元素并不会改变 b 中的元素:
a := [...]int{1, 2, 3} // ... 会自动计算数组长度
b := a
a[0] = 100
fmt.Println(a, b) // [100 2 3] [1 2 3]
**为了避免复制数组,一般会传递指向数组的指针。**例如:
func square(arr *[3]int) {
for i, num := range *arr {
(*arr)[i] = num * num
}
}
func TestArrayPointer(t *testing.T) {
a := [...]int{1, 2, 3}
square(&a)
fmt.Println(a) // [1 4 9]
if a[1] != 4 && a[2] != 9 {
t.Fatal("failed")
}
}
切片
数组固定长度,缺少灵活性,大部分场景下会选择使用基于数组构建的功能更强大,使用更便利的切片类型。
切片使用字面量初始化时和数组很像,但是不需要指定长度:
languages := []string{"Go", "Python", "C"}
或者使用内置函数 make 进行初始化,make 的函数定义如下:
func make([]T, len, cap) []T
第一个参数是 []T,T 即元素类型,第二个参数是长度 len,即初始化的切片拥有多少个元素,第三个参数是容量 cap,容量是可选参数,默认等于长度。使用内置函数 len 和 cap 可以得到切片的长度和容量,例如:
func printLenCap(nums []int) {
fmt.Printf("len: %d, cap: %d %v\n", len(nums), cap(nums), nums)
}
func TestSliceLenAndCap(t *testing.T) {
nums := []int{1}
printLenCap(nums) // len: 1, cap: 1 [1]
nums = append(nums, 2)
printLenCap(nums) // len: 2, cap: 2 [1 2]
nums = append(nums, 3)
printLenCap(nums) // len: 3, cap: 4 [1 2 3]
nums = append(nums, 3)
printLenCap(nums) // len: 4, cap: 4 [1 2 3 3]
}
容量是当前切片已经预分配的内存能够容纳的元素个数,如果往切片中不断地增加新的元素,超过了当前切片的容量,就需要分配新的内存,并将当前切片所有的元素拷贝到新的内存块上。
因此为了减少内存的拷贝次数,容量在比较小的时候,一般是以 2 的倍数扩大的,例如 2 4 8 16 …,当达到 2048 时,会采取新的策略,避免申请内存过大,导致浪费。Go 语言源代码 runtime/slice.go 中是这么实现的,不同版本可能有所差异:
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap // 要分配的长度大于原容量的两倍时 直接分��配
} else {
if old.len < 1024 {
newcap = doublecap // 要分配的长度小于原容量的两倍时 分配两倍
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
切片和数组很相似,按照下标进行索引。切片本质是一个数组片段的描述,包括了数组的指针,这个片段的长度和容量 (不改变�内存分配情况下的最大长度)。
struct {
ptr *[]T
len int
cap int
}
切片操作并不复制切片指向的元素,创建一个新的切片会复用原来切片的底层数组,因此切片操作是非常高效的。下面的例子展示了这个过程:
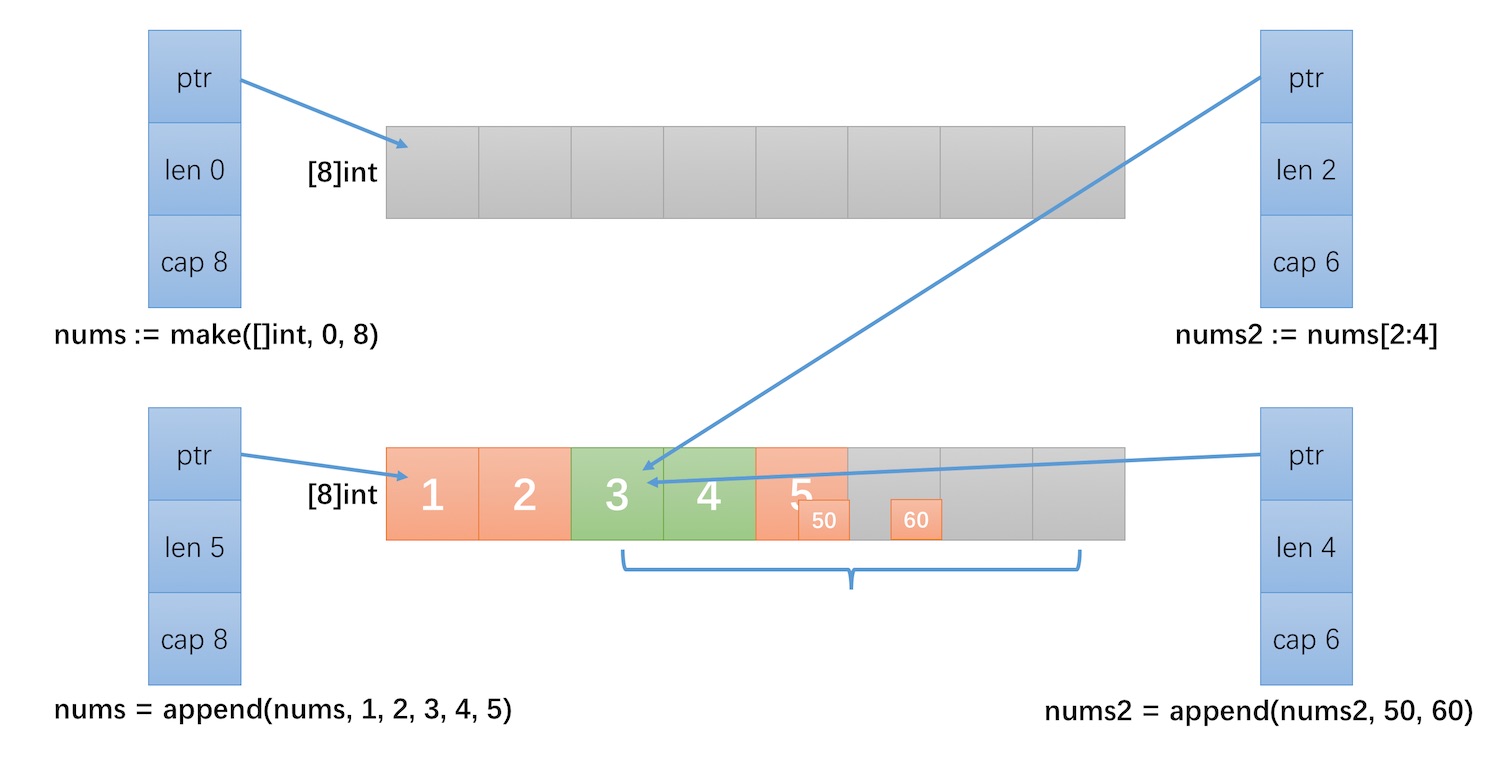
nums := make([]int, 0, 8)
nums = append(nums, 1, 2, 3, 4, 5)
nums2 := nums[2:4]
printLenCap(nums) // len: 5, cap: 8 [1 2 3 4 5]
printLenCap(nums2) // len: 2, cap: 6 [3 4]
nums2 = append(nums2, 50, 60)
printLenCap(nums) // len: 5, cap: 8 [1 2 3 4 50]
printLenCap(nums2) // len: 4, cap: 6 [3 4 50 60]
- nums2 执行了一个切片操作
[2, 4),此时 nums 和 nums2 指向的是同一个数组。 - nums2 增加 2 个元素 50 和 60 后,将底层数组下标 [4] 的值改为了 50,下标 [5] 的值置为 60。
- 因为 nums 和 nums2 指向的是同一个数组,因此 nums 被修改为 [1, 2, 3, 4, 50]。
切片操作及性能
搞清楚切片的本质之后,理解切片的常用操作的性能就容易很多了。
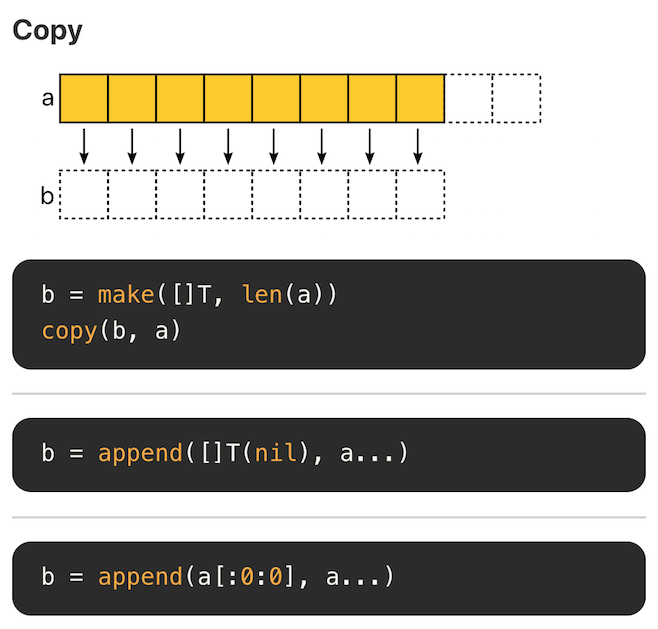
Go 语言在 Github 上的官方 wiki - SliceTricks 介绍了切片常见的操作技巧。另一个项目 Go Slice Tricks Cheat Sheet 将这些操作以图片的形式呈现了出来,非常直观。
Copy
Append
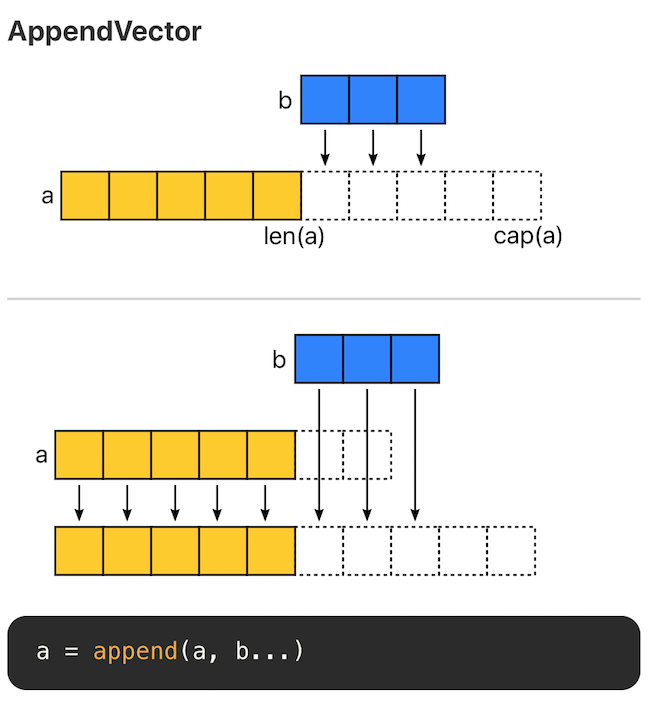
切片有三个属性,指针(ptr)、长度(len) 和容量(cap)。append 时有两种场景:
- 当 append 之后的长度小于等于 cap,将会直接利用原底层数组剩余的空间。
- 当 append 后的长度大于 cap 时,则会分配一块更大的区域来容纳新的底层数组。
因此,为了避免内存发生拷贝,如果能够知道最终的切片的大小,预先设置 cap 的值能够获得最好的性能。
Delete
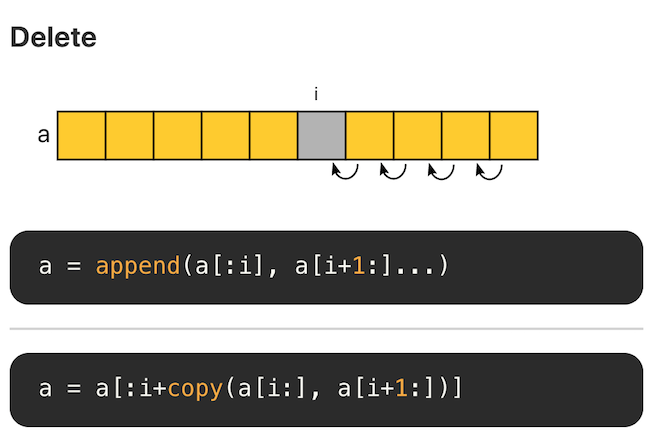
切片的底层是数组,因此删除意味着后面的元素需要逐个向前移位。每次删除的复杂度为 O(N),因此切片不合适大量随机删除的场景,这种场景下适合使用链表。
Delete(GC)
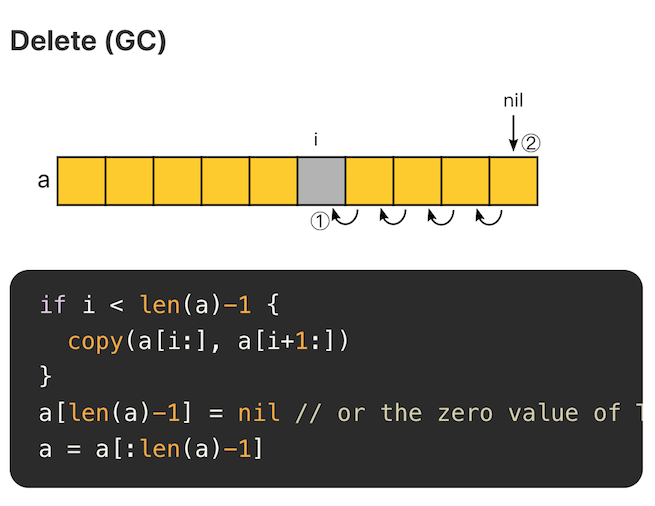
删除后,将空余的位置置空,有助于垃圾回收。
Insert
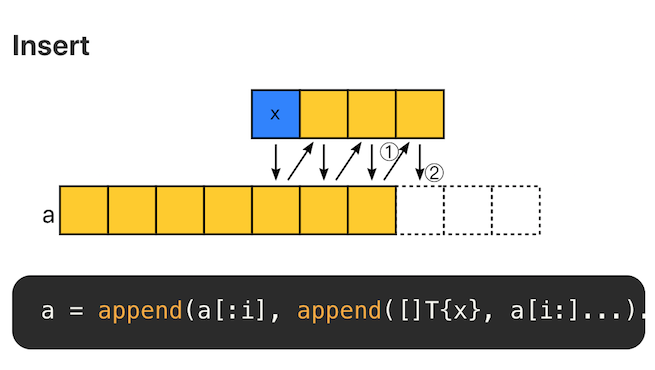
insert 和 append 类似。即在某个位置添加一个元素后,将该位置后面的元素再 append 回去。复杂度为 O(N)。因此,不适合大量随机插入的场景。
Filter
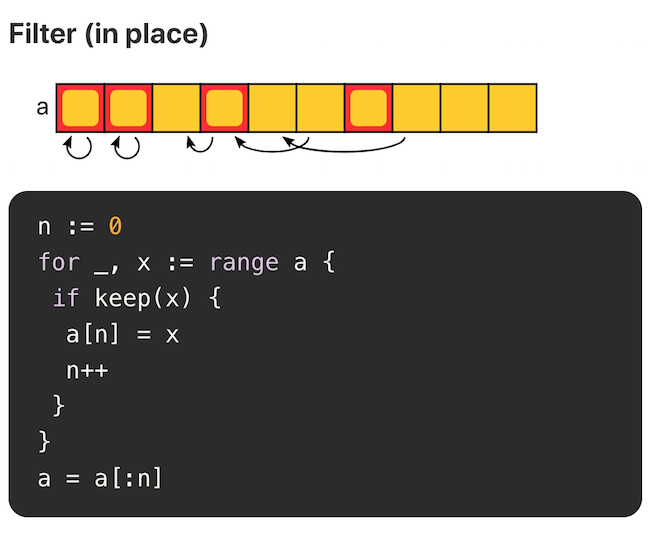
当原切片不会再被使用时,就地 filter 方式是比较推荐的,可以节省内存空间。
Push
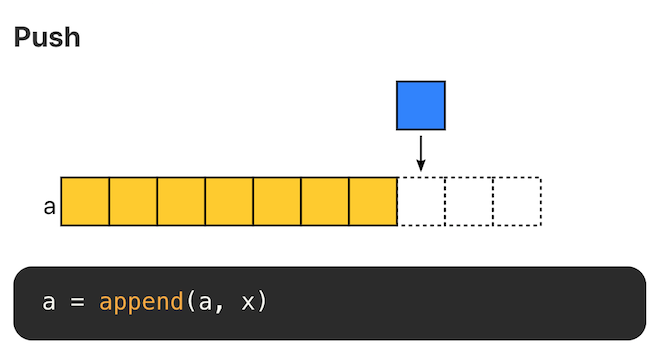
在末尾追加元素,不考虑内存拷贝的情况,复杂度为 O(1)。
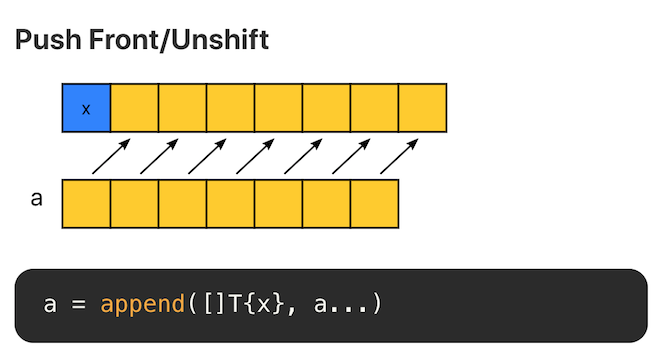
在头部追加元素,时间和空间复杂度均为 O(N),不推荐。
Pop
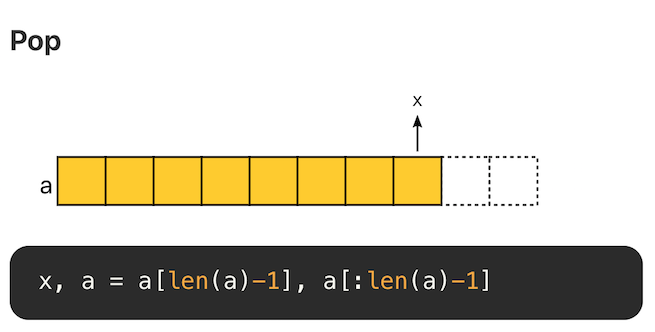
尾部删除元素,复杂度 O(1)
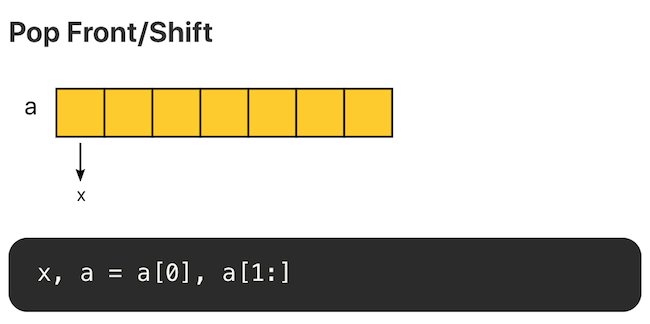
头部删除元素,如果使用切片方式,复杂度为 O(1)。
但是需要注意的是,底层数组没有发生改变,第 0 个位置的内存仍旧没有释放。如果有大量这样的操作,头部的内存会一直被占用。
性能陷阱
大量内存得不到释放
在已有切片的基础上进行切片,不会创建新的底层数组。因为原来的底层数组没有发生变化,内存会一直占用,直到没有变量引用该数组。
因此很可能出现这么一种情况,原切片由大量的元素构成,但是我们在原切片的基础上切片,虽然只使用了很小一段,但底层数组在内存中仍然占据了大量空间,得不到释放。
比较推荐的做法,使用 copy 替代 re-slice。
func lastNumsBySlice(origin []int) []int {
return origin[len(origin)-2:]
}
func lastNumsByCopy(origin []int) []int {
result := make([]int, 2)
copy(result, origin[len(origin)-2:])
return result
}
上述两个函数的作用是一样的,取 origin 切片的最后 2 个元素。
- 第一个函数直接在原切片基础上进行切片。
- 第二个函数创建了一个新的切片,将 origin 的最后两个元素拷贝到新切片上,然后返回新切片。
我们可以写两个测试用例来比较这两种方式的性能差异:
在此之前呢,我们先实现 2 个辅助函数:
func generateWithCap(n int) []int {
rand.Seed(time.Now().UnixNano())
nums := make([]int, 0, n)
for i := 0; i < n; i++ {
nums = append(nums, rand.Int())
}
return nums
}
func printMem(t *testing.T) {
t.Helper()
var rtm runtime.MemStats
runtime.ReadMemStats(&rtm)
t.Logf("%.2f MB", float64(rtm.Alloc)/1024./1024.)
}
generateWithCap用于随机生成 n 个 int 整数,64 位机器上,一个 int 占 8 Byte,128 * 1024 个整数恰好占据 1 MB 的空间。printMem用于打印程序运行时占用的内存大小。
接下来分别为 lastNumsBySlice 和 lastNumsByCopy 实现测试用例:
func testLastChars(t *testing.T, f func([]int) []int) {
t.Helper()
ans := make([][]int, 0)
for k := 0; k < 100; k++ {
origin := generateWithCap(128 * 1024) // 1M
ans = append(ans, f(origin))
}
printMem(t)
_ = ans
}
func TestLastCharsBySlice(t *testing.T) { testLastChars(t, lastNumsBySlice) }
func TestLastCharsByCopy(t *testing.T) { testLastChars(t, lastNumsByCopy) }
- 测试用例内容非常简单,随机生成一个大小为 1 MB 的切片( 128*1024 个 int 整型,恰好为 1 MB)。
- 分别调用
lastNumsBySlice和lastNumsByCopy取切片的最后两个元素。 - 最后然后打印程序所占用的内存。
运行结果如下:
$ go test -run=^TestLastChars -v
=== RUN TestLastCharsBySlice
--- PASS: TestLastCharsBySlice (0.31s)
slice_test.go:73: 100.14 MB
=== RUN TestLastCharsByCopy
--- PASS: TestLastCharsByCopy (0.28s)
slice_test.go:74: 3.14 MB
PASS
ok example 0.601s
结果差异非常明显,lastNumsBySlice 耗费了 100.14 MB 内存,也就是说,申请的 100 个 1 MB 大小的内存没有被回收。因为切片虽然只使用了最后 2 个元素,但是因为与原来 1M 的切片引用了相同的底层数组,底层数组得不到释放,因此,最终 100 MB 的内存始终得不到释放。
而 lastNumsByCopy 仅消耗了 3.14 MB 的内存。这是因为,通过 copy,指向了一个新的底层数组,当 origin 不再被引用后,内存会被垃圾回收 (garbage collector, GC)。
如果我们在循环中,显示地调用 runtime.GC(),效果会更加地明显:
func testLastChars(t *testing.T, f func([]int) []int) {
t.Helper()
ans := make([][]int, 0)
for k := 0; k < 100; k++ {
origin := generateWithCap(128 * 1024) // 1M
ans = append(ans, f(origin))
runtime.GC()
}
printMem(t)
_ = ans
}
lastNumsByCopy 内存占用直接下降到 0.15 MB。
$ go test -run=^TestLastChars -v
=== RUN TestLastCharsBySlice
--- PASS: TestLastCharsBySlice (0.37s)
slice_test.go:75: 100.14 MB
=== RUN TestLastCharsByCopy
--- PASS: TestLastCharsByCopy (0.34s)
slice_test.go:76: 0.15 MB
PASS
ok example 0.723s
for 和 range 的性能比较
range 的简单回顾
Go 语言中,range 可以用来很方便地遍历数组 (array)、切片 (slice)、字典 (map) 和信道 (chan)
array/slice
words := []string{"Go", "语言", "高性能", "编程"}
for i, s := range words {
words = append(words, "test")
fmt.Println(i, s)
}
输出结果如下:
0 Go
1 语言
2 高性能
3 编程
- 变量 words 在循环开始前,仅会计算一次,如果在循环中修改切片的长度不会改变本次循环的次数。
- 迭代过程中,每次迭代的下标和值被赋值给变量 i 和 s,第二个参数 s 是可选的。
- 针对 nil 切片,迭代次数为 0。
range 还有另一种只遍历下标的写法,这种写法与 for 几乎没什么差异了。
for i := range words {
fmt.Println(i, words[i])
}
输出也是一样的:
0 Go
1 语言
2 高性能
3 编程
map
m := map[string]int{
"one": 1,
"two": 2,
"three": 3,
}
for k, v := range m {
delete(m, "two")
m["four"] = 4
fmt.Printf("%v: %v\n", k, v)
}
输出结果为:
one: 1
four: 4
three: 3
- 和切片不同的是,迭代过程中,删除还未迭代到的键值对,则该键值对不会被迭代。
- 在迭代过程中,如果创建新的键值对,那么新增键值对,可能被迭代,也可能��不会被迭代。
- 针对 nil 字典,迭代次数为 0
channel
ch := make(chan string)
go func() {
ch <- "Go"
ch <- "语言"
ch <- "高性能"
ch <- "编程"
close(ch)
}()
for n := range ch {
fmt.Println(n)
}
- 发送给信道 (channel) 的值可以使用 for 循环迭代,直到信道被关闭。
- 如果是 nil 信道,循环将永远阻塞。
for 和 range 的性能比较
[]int
func generateWithCap(n int) []int {
rand.Seed(time.Now().UnixNano())
nums := make([]int, 0, n)
for i := 0; i < n; i++ {
nums = append(nums, rand.Int())
}
return nums
}
func BenchmarkForIntSlice(b *testing.B) {
nums := generateWithCap(1024 * 1024)
for i := 0; i < b.N; i++ {
len := len(nums)
var tmp int
for k := 0; k < len; k++ {
tmp = nums[k]
}
_ = tmp
}
}
func BenchmarkRangeIntSlice(b *testing.B) {
nums := generateWithCap(1024 * 1024)
for i := 0; i < b.N; i++ {
var tmp int
for _, num := range nums {
tmp = num
}
_ = tmp
}
}
运行结果如下:
$ go test -bench=IntSlice$ .
goos: darwin
goarch: amd64
pkg: example/hpg-range
BenchmarkForIntSlice-8 3603 324512 ns/op
BenchmarkRangeIntSlice-8 3591 322744 ns/op
generateWithCap用于生成长度为 n 元素类型为 int 的切片。- 从最终的结果可以看到,遍历
[]int类型的切片,for 与 range 性能几乎没有区别。
[]struct
那如果是稍微复杂一点的 []struct 类型呢?
type Item struct {
id int
val [4096]byte
}
func BenchmarkForStruct(b *testing.B) {
var items [1024]Item
for i := 0; i < b.N; i++ {
length := len(items)
var tmp int
for k := 0; k < length; k++ {
tmp = items[k].id
}
_ = tmp
}
}
func BenchmarkRangeIndexStruct(b *testing.B) {
var items [1024]Item
for i := 0; i < b.N; i++ {
var tmp int
for k := range items {
tmp = items[k].id
}
_ = tmp
}
}
func BenchmarkRangeStruct(b *testing.B) {
var items [1024]Item
for i := 0; i < b.N; i++ {
var tmp int
for _, item := range items {
tmp = item.id
}
_ = tmp
}
}
先看下 Benchmark 的结果:
$ go test -bench=Struct$ .
goos: darwin
goarch: amd64
pkg: example/hpg-range
BenchmarkForStruct-8 3769580 324 ns/op
BenchmarkRangeIndexStruct-8 3597555 330 ns/op
BenchmarkRangeStruct-8 2194 467411 ns/op
- 仅遍历下标的情况下,for 和 range 的性能几乎是一样的。
items的每一个元素的类型是一个结构体类型Item,Item由两个字段构成,一个类型是 int,一个是类型是[4096]byte,也就是说每个Item实例需要申请约 4KB 的内存。- 在这个例子中,for 的性能大约是 range (同时遍历下标和值) 的 2000 倍。
[]int 和 []struct{} 的性能差异
与 for 不同的是,range 对每个迭代值都创建了一个拷贝。因此如果每次迭代的值内存占用很小的情况下,for 和 range 的性能几乎没有差异,但是如果每个迭代值内存占用很大,例如上面的例子中,每个结构体需要占据 4KB 的内存,这种情况下差距就非常明显了。
我们可以用一个非常简单的例子来证明 range 迭代时,返回的是拷贝。
persons := []struct{ no int }{{no: 1}, {no: 2}, {no: 3}}
for _, s := range persons {
s.no += 10
}
for i := 0; i < len(persons); i++ {
persons[i].no += 100
}
fmt.Println(persons) // [{101} {102} {103}]
persons是一个长度为 3 的切片,每个元素是一个结构体。- 使用
range迭代时,试图将每个结构体的 no 字段增加 10,但修改无效,因为 range 返回的是拷贝。 - 使用
for迭代时,将每个结构体的 no 字段增加 100,修改有效。
[]*struct{}
那如果切片中是指针,而不是结构体呢?
func generateItems(n int) []*Item {
items := make([]*Item, 0, n)
for i := 0; i < n; i++ {
items = append(items, &Item{id: i})
}
return items
}
func BenchmarkForPointer(b *testing.B) {
items := generateItems(1024)
for i := 0; i < b.N; i++ {
length := len(items)
var tmp int
for k := 0; k < length; k++ {
tmp = items[k].id
}
_ = tmp
}
}
func BenchmarkRangePointer(b *testing.B) {
items := generateItems(1024)
for i := 0; i < b.N; i++ {
var tmp int
for _, item := range items {
tmp = item.id
}
_ = tmp
}
}
运行结果如下:
goos: darwin
goarch: amd64
pkg: example/hpg-range
BenchmarkForPointer-8 271279 4160 ns/op
BenchmarkRangePointer-8 264068 4194 ns/op
切片元素从结构体 Item 替换为指针 *Item 后,for 和 range 的性能几乎是一样的。而且使用指针还有另一个好处,可以直接修改指针对应的结构体的值。
⭐ 总结
range 在迭代过程中返回的是迭代值的拷贝,如果每次迭代的元素的内存占用很低,那么 for 和 range 的性能几乎是一样,例如 []int。
但是如果迭代的元素内存占用较高,例如一个包含很多属性的 struct 结构体,那么 for 的性能将显著地高于 range,有时候甚至会有上千倍的性能差异。对于这种场景,建议使用 for,如果使用 range,建议只迭代下标,通过下标访问迭代值,这种使用方式和 for 就没有区别了。
如果想使用 range 同时迭代下标和值,则需要将切片/数组的元素改为指针,才能不影响性能,同时又能方便地修改元素。